아키텍처
아키텍처의 정의
하드웨어와 소프트웨어를 포함한 시스템 구조
아키텍처를 알아야하는 이유
- 새로운 버전의 DBMS를 경험이 아닌 원리 구조를 가지고 빠른 파익이 가능함.
- 다른 DBMS 또한 데이터베이스 이론을 기반으로 설계 구현된 것이라 다른 DBMS를 다루는데 필요함.
- 새로운 문제가 발생했을 때 배우지 않아도 구조적으로 이해하고 파악하여 처리가 가능함.
성능관점 아키텍처
- 튜닝을 위해 아키텍처의 구조를 아는 것은 중요함
- 개발자가 충분히 처리 가능한 소프트웨어 튜닝 영역으로 한정함.
- DBA가 할 수 있는 영역과 다름.
Oracle DBMS 구조
Instance
자바의 인스턴스와 같은 의미, 즉 메모리상에 올라와 실행 가능한 상태
메모리(SGA : SytstemGlobalArea)
- Data Buffer Cache
- 사용자가 요청한 데이터를 저장하는 메모리 영역
- Select 실행 후 결과 집합을 Data Buffer Cache에 저장함.
- Shared Pool
- SQL, PL/SQL을 공유하기 위한 영역
- Redo Log Buffer
- 작업내용을 Log로 남김
- 데이터 복구
- Data Buffer Cache
Background Process
- User Process
- SQL 명령어를 Oracle DBMS에게 보내는 프로세스
- Server Process
- SQL을 받아 서비스하는 프로세스
- User Process
데이터 저장구조

- Table Space
- TableSpace는 여러 Block으로 구성된다.
- TableSpace에 데이터가 가득 차게 되면 TableSpace를 확장한다.
- TableScpae에 Block이 연속적으로 할당되는 이유는 검색의 효율을 높이기 위함이다.
- Extent
- Extent는 연속된 Block영역
- Block
- Block은 하나의 Cell을 의미하며 데이터가 저장되는 공간을 의미한다.
데이터 저장구조, 계층적 저장구조

- Database는 1개 이상의 TableSpace가 반드시 있어야 함.
- TableSpace는 반드시 1개의 Database에 포함되어야 함.
- 실제 운영되는 Database는 여러 TableSpace로 구성됨.
TableSpace와 Segment의 관계
- TableSpace는 논리적인 저장공간
- Segment는 TableSpace 내에 저장되어 자신만의 저장영역을 확보하는 물리적인 DatabaseObject이며 대표적으로 테이블과 인덱스가 있음
- TableSpace는 1개 이상의 Segment가 저장될 수 있음.
File/Extent/Block
File
TableSpace는 여러 개의 물리적인 파일들로 구성되어 있음
Extent
Segment는 1개 이상의 Extent로 구성됨.
Block
- Extent는 1개 이상의 Block으로 구성됨.
- Block은 I/O의 최소단위.
- Block의 크기는 2K, 4K ~ 32K의 크기를 가질 수 있음.
- Block은 I/O의 최소 단위이기 때문에 Block안에 해당하는 레코드가 수정되면 Block단위로 수정됨.
ROWID

- 객체의 Row가 저장된 논리적 주소값
- ROWID를 가지고 데이터를 찾는 것이 가장 빠른 길임.
SQL 처리 과정
목표
SQL 처리과정을 이해하자.
SQL 이란
- 관계형 DBMS에 접근하는 유일한 언어
- ANSI-SQL
- 표준 SQL
- ANSI-SQL을 잘 익혀 두면 다른 RDBMS로 이식이 쉬움
- SQL의 주요 특징
- English-Like
- 영어 문맥과 유사함
- 대소문자를 구분하지 않음
- 비절차적 언어
- English-Like
Server Process
- Connection과 Session
- Server Process는 User Process(웹 서버, RDBMS)로부터 Connection을 생성하고 Session을 통해 Connection에 연결된 User의 정보를 관리함.
- User Process는 Server Process에 SQL (문자열)을 전송한다. 즉 이를 SQL 실행이라고 함.
SQL처리
Parsing > Execution > Fetch
Fetch는 서버에서 클라이언트로 데이터를 옮겨 표현하는 과정으로 DML(Insert, Delete, Update)에서는 Fetch과정이 존재하지 않음
Parsing 단계
Syntax Check
- SQL 명령어의 문법적 오류를 Check하는 단계
Semantic Check
- SQL 명령어의 의미적인 오류를 Check하는 단계
- 데이터베이스 객체(Table, Index, Sequence, 등..)의 유효성 검사, 접근 권한검사 등을 수행함
Execution Plan 수립
- 질의 최적화기(Query Optimizer)가 최적화된 실행계획을 수립하는 단계
Execution 단계
- Parsed-Tree를 가지고 Server Process가 명령어를 실행하는 단계임

- Parsed-Tree를 가지고 Server Process가 명령어를 실행하는 단계임
Fetch 단계
- Select의 경우에만 실행되는 단계
- Execution 단계에서 준비된 결과 데이터를 사용자에게 전달하는 과정임
Parsing 후 SQL 문장, 실행계획, Parsed-Tree를 DBMS가 관리하는 Shared SQL, PL/SQL Area라는 메모리 영역에 저장됨
- Semantic Check, Execution Plan 수립은 CPU를 많이 사용하고, DBMS의 내부 공유자원에 대한 제어를 많이 사용함
- 그렇기 때문에 Parsing 작업을 줄이기 위해 Shared Pool 내 Library Cache에 Parsing 결과물을 저장해두고 SQL을 재사용함.
- SoftParsing vs HardParsing
- SoftParsing은 Cache hit로 기존 Parsing된 결과물을 재사용함
- HardParsing은 Cache miss로 Parsing 단계를 진행함
Select 처리 구조
- SGA의 Data Buffer Cache를 탐색한 후 데이터가 존재하지 않으면 검색 시작.
- LRU(Least Recent Used : 최근 자주 사용된 것을 유지) 관리정책으로 Shared Pool과 Data Buffer Cache를 관리함.
DML 처리 구조
- Update, Delete
- Redo log Buffer 변경전/변경후/변경행위 기록 [작업내용 선 입력]
- Undo Block 변경 전 데이터 기록 [Rollback을 위함]
- 물리 데이터에 변경 정보 저장 [DBWR이 작업을 진행함]
- Insert
- Redo log Buffer 변경전/변경후/변경행위 기록 [작업내용 선 입력]
- Insert할 Block Cache할당
- 물리 데이터에 변경 정보 저장
- Update, Delete
Delete vs Truncate
- Delete 데이터를 삭제하기 위해 Redo Data, Undo Data를 기록해야함.
- Truncate는 Redo Data, Undo Data를 만들지 않음. DataDictionary에 삭제처리한 후 끝남.
- 그렇기 때문에 Truncate의 속도가 훨씬 빠름
DBWR(Database Writer)
Data Buffer Cache의 변경된 정보를 한꺼번에 효율적으로 모아서 Data File에 기록함.
LGWR
Redo Log Buffer의 로그 정보를 Log File에 기록함.
모니터링
성능 모니터링 원리 및 구조
- 모니터링 -> 진단 및 분석 -> 문제해결
- DBMS 운영 중 발생 상황 -> SGA 가상 테이블 메모리에 구조체 형식으로 저장
- 가상테이블 -> 동적성능테이블(X$), 가상뷰 -> 동적성능뷰(V$)
- 동적의 2가지 의미
- DBMS 운영 중에 수치 값이 계속 변함
- DBMS 종료 시 DataFile에 저장하지 않고 지움
DBA 권한
- 주로 V$ 테이블의 경우 DBA의 권한으로 되어 있음
- DBA들이 자주 사용하는 동적 성능 뷰
Server Process 방식
- DBA 설정에 따라 달라짐
- Dedicated Server Process
- User Process Server Process 1:1
- PGA(Program Global Area)
- 해당 서버가 단독으로 사용하는 메모리 영역
- User Process 요청이 올 때마다 H/W서버에 Server Process 생성
- 기본적으로 Dedicated Server Process를 사용함
- Shared Server Process
- UserProcess Server Process N:1
- 동일한 자원으로 더 많은 유저 처리를 할 수 있음
- 유저 처리가 많아질수록 Dedicated Server 방식보다 대응 처리가 늦어질 수 있음
- Parallel Processing
- 대용량은 병행처리, 소용량은 싱글처리하는 것이 효율적이다.
- 대용량 병행처리를 위해서는 업무분석 -> 업무분담 -> 업무병합 작업이 진행되므로 소용량은 싱글처리가 빠른 것이다.
- 대용량 병행처리도 많은 프로세서가 참여하면 자원 경쟁으로 인해 속도 저하가 발생할 수 있다.

- /+/ 로 병행처리 힌트 전달
- 실행계획 수립에서 Optimizer가 병행처리 여부 판단
- Query Coordinator가 조정자, Slave Process Pool에서 Slave Process를 가지고 병행처리를 진행함.
Execution Plan
- 실행계획을 보면서 SQL DBMS 내부에서 어떻게 처리되는지 내부 처리 절차를 들여다 보는 것이다
- SQL 튜닝 시 확인
- 실행계획 분석
- Explain Plan 명령어
- Autotrace OPTION

성능튜닝 개요
목표
- 성능튜닝의 주체
- 성능튜닝의 시기
- 성능튜닝의 적용
누가 튜닝하는가?
- 개념적/논리적 데이터 모델링 튜닝
- 모델러
- 물리적 모델링 측면의 Object 튜닝
- DBA, 개발 PL
- SQL 튜닝, 데이터 처리 Logic 튜닝
- 개발자, 튜너
- DBMS Configuration 튜닝 (SGA 크기, I/O 분산, INSTANCE 튜닝)
- DBA
- OS Configuration 튜닝
- 시스템 관리자
- 개념적/논리적 데이터 모델링 튜닝
무엇을 튜닝하는가?


튜닝 Step
- 개발중인 시스템에 대해 튜닝을 수행할 때 순서대로 진행하는 것이 비용대비 효과면에서 유리
Tune Design
- DB 모델링 튜닝
- 개념모델링 -> 논리모델링 -> 물리모델링
Tune Application
- Server Tuning
- DBMS, OS, H/W
- Application Tuning
- Application Source
- Server Tuning
Tune Memory
- 적절한 메모리 사이징
- Data Buffer Cache
Tune I/O
I/O 최소화 (어플리케이션 개발자)
SQL 튜닝
Tune Contention, Tune O/S
- Lock과 관련된 부분
성능 튜닝의 시기


- 개발자 단계
- SQL 기능 구현
- Application 적용 후 개발
- 튜닝이 적용된 개발자 단계
- SQL 기능 구현
- SQL 성능 Test 및 튜닝
- Application 적용 후 개발
- 개발자 단계

성능진단 성능튜닝
- 목표
- 성능튜닝의 분석항목
- 성능튜닝 Tool을 통한 튜닝 진행
- 성능튜닝 분석항목
- 자원사용량 분석
- 실행계획, 접근경로
- 응답시간
- 자원사용량 분석



- Query는 Select, Current는 DML을 말함
- 8K block이라고 할 때, 7568 * 8K = 59MB를 읽어드림
- 1개의 로우를 읽기 위해 59MB Physical Read, Logical Read가 발생함.
- 실행계획, 접근경로
- 실행계획 = 접근경로 + 연산
- 큰 성능 차이는 접근경로를 통해 나타나기 때문에, Optimizer가 선택한 접근경로를 잘 파악하는 것이 중요하다.
- 접근경로
- Direct Access
- ROWID를 통한 접근
- Index Scan
- Direct Access
- Full Table Scan
- 성능튜닝 툴
- PLAN_TABLE
- utlxplan.sql을 실행하여 PLAN_TABLE을 개발자가 생성할 수 있다.
- Oracle Tool
- SQL Trace
- 필수적인 Tool
- Autotrace
- 편리한 Tool
- DBA 도움이 있어야함.
- DBA 계정으로만 가능 (sys 로그인)
- sql로 설치 (@경로/파일명)
- set autotrace on 입력 후 쿼리
- SQL Trace
- PLAN_TABLE
explain plan
개발자가 쓰기 편함
DBMS_XPLAN 으로 강력한 지원
explain for 쿼리

Explain for 쿼리 후
Select * from table(DBMS_XPLAN.DISPLAY); 로 분석결과를 볼 수 있음
SQL Trace
- DBA 주요 툴
- 강력한 툴이지만 전문성이 요구
- *.trc 파일 생성
- Tkprof로 파일 열기(읽기 쉬운 형태로 보여줌)
statspack
- sql로 설치(@ORACLE_HOME\RDBMS\ADMIN*, DBA용 설치 툴)
- 구간성능 모니터링
- EXECUTE STATSPACK.SNAP 으로 시작
- EXECUTE STATSPACK.SNAP 으로 종료
성능 시뮬레이션 1
목표
- 빈번한 DB Connection
- 빈번한 Hard Parsing
- 빈번한 Fetch
- 위 경우에 대한 사례 및 아케텍쳐와 해결방안 학습
빈번한 DB Connection
- 유저의 요청이 들어오면, 유저의 요청을 받는 리스너는 서버 프로세스를 만들고 서버 프로세스는 SGA에 Session 정보를 만듬.
- 프로세스를 만드는 작업은 OS가 진행하며 많은 자원이 소모됨.
- 서버 프로세스보다 전체 CPU 사용량이 높은 것으로 보아 서버프로세스 보다 OS자원 사용량이 더 많은 것을 알 수 있음

해결방안
- Conneciton Pool을 만들어 빈번한 Connection 생성 및 제거를 줄일 수 있다.
빈번한 Hard Parsing

- SQL 처리 단계
- Parsing
- SQL문
- 실행계획 (Execution Plan)
- Parsed Tree
- Execution
- Fetch
- Parsing
- 파싱된 SQL문은 SGA에서 캐시에 저장되어 효율성을 높인다.
- SQL 처리 단계
- 캐시의 경우 LRU(Least Recently Used) 정책을 사용하여 캐시를 관리한다.
해결방법
SQL 공유
컴파일된 SP를 사용하여 Hard Parsing을 줄인다.
조건을 바인드 변수 처리
문자열로 조건을 넘기는 것이 아닌 바인드로 처리하면 SQL을 재사용할 수 있음
‘SELECT * FROM EMP WHERE EMP_ID’ || TO_CHAR(EMP_ID) (잘못사용X)
‘SELECT * FROM EMP WHRE EMP_ID = :EMP_ID ‘; (바인딩)
바인드 변수의 문제점
바인드 변수의 경우 기존의 SQL을 사용함으로 같은 실행계획을 동일하게 사용함 soft parsing
균등한 데이터 분포도를 가진 컬럼에서 사용해야함
인덱싱된 컬럼에 대해 조회를 처리할 시 인덱싱하는 데이터의 양이 불균등하게 많은 데이터 검색 시 Full Table Scan이 효율적이고 적당하게 분표한 데이터의 경우 Index Scan의 효율적이기 때문임

DBA가 인스턴스 파라미터 사용
1:10:100의 원리
- 초기에 해결하면 1, 중기에 해결하면 10, 말기에 해결하면 100
HardParsing 문제를 개발전에 계획수립시 개발정책으로 결정하여 사전에 미리 문제를 해결해야함.
빈번한 Fetch
- 1번 Fetch시 여러 개의 데이터를 묶어서 보냄
- Array Size를 설정하여, 빈번하게 발생하는 Fetch(DBMS Call)을 줄인다.
- 전체범위처리, 부분범위처리
- 30만건의 데이터를 예시로, 30만건을 전체 다보내면 전체범위처리, 30만건을 30개씩 요청에 따라 나눠보내면 부분범위 처리이다
- 특성에 맞게 사용하는 것이 중요하다.
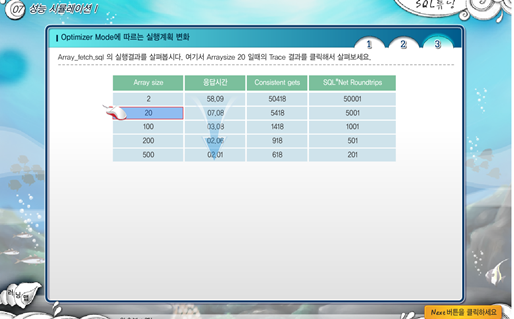
- Consistent gets은 데이터를 위해 block에 접근한 횟수를 의미함.
- 10block * 1 = 10 (consistent gets)
- 1block * 10 = 10 (consistent gets)
성능 시뮬레이션2
- 목표
- 시뮬레이션을 통해 효과적인 데이터 처리방식을 알아보자.
- 툴마다 지원하는 명령어가 있다
- Sqlplus
- Rem
- @
- Sqlplus
- Set 변수 값
PL/SQL
- Procedural Language Extension to SQL(절차언어 SQL)
- PL/SQL의 명령어는 절차적으로 진행됨
- DBMS SQL을 만나면 데이터베이스에 데이터 요청을 하게 됨(DBMS CALL)
- 잦은 DBMS CALL은 결국 성능저하를 야기함.
- 네트워크 데이터 전송에 따른 시간 감축
PL/SQL Array Processing
빈번한 DBMS CALL을 줄이기 위한 처리방법
ArraySize 크기 만큼 데이터를 가져와 처리 (ArraySize 변동에 따른 시간 체크)
FETCH TEST_CURSOR BULK COLLECT INTO ..
FORALL I IN 1..
- 횟수만큼 바인딩 후 한번에 INSERT
Stored Procedural

Stored Block을 통해서 SQL 파싱 시간을 감소
유저간 공유 가능
절차적 처리와 비절차적 처리


SQL문을 전송하여 한번에 집합적으로 처리
FETCH, INSERT를 하는 것이 아니기 때문에 빈번한 DBMS Call이 발생하지 않고, 빈번한 Context Switch가 발생하지 않음(연산작용과 DBMS Call간의 데이터 스위치를 의미). 또한 단위를 20개로 나누워 절차적으로 처리하지 않음
LG
- 비절차적 방식으로 주로 데이터를 처리함
- 필요한 경우 FETCH하여 데이터를 가져온 후 비절차로 처리
- 그러기 때문에 Array Processing은 필요없겠구나.
- Stord Procedural
- 비절차적 처리

옵티마이저
목표
- Optimizer 개념
- Optimizer 종류
- Optimizer Mode에 따른 실행계획 차이
Optimizer의 개념

- 비절차적 언어인 SQL은 RDBMS에 쿼리를 보내면 RDBMS의 Optimizer는 해당 요청에 대한 실행계획을 실행함.
- 절차적 언어인 Java는 개발자가 효율적인 처리 절차를 기술해야함

Optimizer의 한계
Optimizer의 한계성, 주변상황, 판단조건 수립된 실행계획이 항상 최적화된 정답은 아니다.
Optimizer를 완벽히 이해하기는 힘들지만, 어느정도 이해를 하고 있어야 오판 원인 진단을 할 수 있다.
오판을 바로 잡는 것이 바로 튜닝이다.
Optimizer의 종류
- CFO형
- 주변사항에 따라 효율이 좋은 판단을 내림
- 행동대장형
- 규칙에 따라서 판단을 내림
- CFO가 가끔 오판을 하지만 행동대장형보다 주변 상황에 따른 최적의 판단을 하기 때문에 대세임
- RBO (Rule Base Optimizer, 행동대장형)
- 규칙기반 Optimizer
- 미리 정해진 고정된 15개의 규칙을 기반으로 판단
- CBO(Cost Base Optimizeer, CFO형)
- 비용기반 Optimizer
- Data Dictionary 들에 저장된 통계정보 기반 판단
- Full Table Scan, Index Scan 판단하기
- Full Table Scan은 전체 검색, 검색하려는 데이터가 많을수록 Full Table Scan이 유리
- Index Scan은 색인 참조 후 Direct Access 이므로, 검색하려는 데이터가 적을 수록 Index Scan이 유리
- CBO가 최적화된 실행계획을 수립할 수 있도록 하려면?
- Analyze 명령어 , dbms_stat 패키지는 통계정보 수집 기능을 가지고 있음.
- 주기적인 통계정보 갱신을 통해 정확성 있는 정보를 유지해야함
- CFO형
- 통계정보 갱신은 DBA의 업무
Oracle의 CBO 비용공식은 아마도(비공개) Row Cadinality, I/O Cost, Network Cost, Cpu Cost등을 종합적으로 산정
CBO와 RBO이 장단점

- 한마디로 RBO은 사장 기술 이고만
Optimizer 모드

- ALL_ROWS, FULL TABLE SCAN
- FIRST_ROWS, INDEX SCAN
- RULE, RBO
- CHOOSE, CBO, RBO 중 택일
- /+/힌트로 Optimizer에게 힌트를 줌.
- Optimzer 판단으로 힌트대로 실행하거나 무시함
- ANALYZE 명령어로 통계를 수집, 삭제
- 데이터딕셔너리는 여러 테이블로 구성되어있군.
- 통계정보는 데이터딕셔너리에 저장됨 (USER_TABLES)
- ANALYZE TABLE 테이블명 ESTIMATE STATISTICS FOR COLUMNS 병역종류;
- 분포도가 일정하지 않은 경우 CBO는 잘못된 판단을 할 경우 가 큼, 분포도에 따라 접근경로가 달라지기 떄문임
- 분포가 많은 데이터는 Full Table Scan으로
- 분포가 적은 데이터는 Index Scan이 효율적임.
- DBA_HISTOGRAMS에 분포도 저장
- USER_TAB_COLUMNS에 데이터 밀도 저장
- 검색할 컬럼에 대한 분포도를 알아야 FULL TABLE SCAN, INDEX SCAN이 맞는지 알 수 있음 CBO 계산 정보
- 분포도가 일정하지 않은 경우 CBO는 잘못된 판단을 할 경우 가 큼, 분포도에 따라 접근경로가 달라지기 떄문임
